What is etcd?
etcd is a distributed key-value database where kubernetes stores the kubernetes clusters configuration and its state. By default when we launch cluster on kops it sets up etcd cluster on the master nodes with etcd-manager and etcd-events running on separate containers. In kops using aws as provider Etcd stores its data and their respective certs inside attached EBS volumes for both etcd-manager and etcd-events.
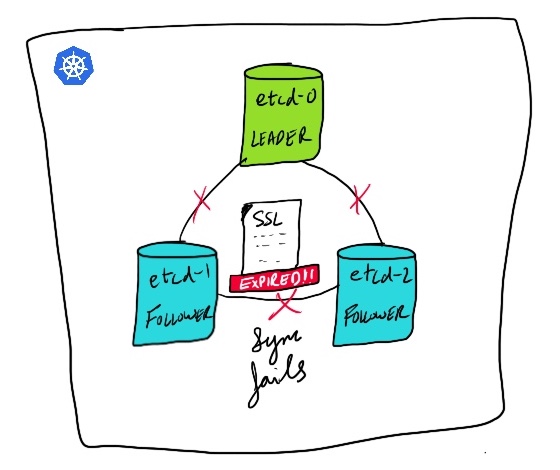
Etcd uses RAFT algorithm to make sure the data is synced between leader and follower nodes. Whenever there is a write in request it goes through leader and then is replicated across the followers and the success response is returned, and when read happens on any of the follower it checks and makes sure the data persists on leader and then response is returned. All these processes take millseconds to do the operations and is blazingly fast.
the issue :/
So recently our etcd nodes failed and in the logs we started seeing error like:
embed: rejected connection from "10.0.x.x:16524" (error "remote error: tls: bad certificate", ServerName "ecd-events-c.our.domain")
embed: rejected connection from "10.0.x.x:46636" (error "remote error: tls: bad certificate", ServerName "ecd-events-c.our.domain")
x509: certificate has expired or is not yet valid (prober "ROUND_TRIPPER_RAFT_MESSAGE")
Running a component status check on kubernetes showed unhealthy status for our etcd:
kubectl get cs
NAME STATUS MESSAGE ERROR
etcd-0 Unhealthy Get https://127.0.0.1:4001/health..
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Unhealthy
Let the investigation begin
So we started to look for the certificates and logged into our master node.
Certs in side /etc/kubernetes/pki
It was very clear after seeing the error that it was an issue related to certificate expiring on one of these etcd-nodes. So we logged into our master nodes and went inside /etc/kubernetes/pki and found the directories for etcd which in turn have multiple certs:
admin@ip-10-0-x-x:/etc/kubernetes/pki$ ls
etcd-manager-events etcd-manager-main kube-apiserver
Then inside the directory I built a quick one line script to check for certificate expiry to find the expired certificate:
for file in /rootfs/etc/kubernetes/pki/etcd-manager-events/*; do echo "$file:"; openssl x509 -in $file -text | grep 'Not Before\|Not After'; done
But all the certs inside etcd-manager-events, etcd-manager-main and even in kube-apiserver were well set to expire the next year and now we knew that these are probably not the certificates the logs are complaining about.
Certs in EBS volume
As I learnt that etcd stores its data in mounted EBS volume at /mnt/master-vol-****, so I decided to look in there just to explore the data and there I found another pki directory. So inside this /mnt/master-vol-****/pki/<random-hash>/ there were clients and peers directories with certs.
/mnt/master-vol-010585f3ee8b8153c/pki/<random-hash>/clients$ ls
ca.crt server.crt server.key
/mnt/master-vol-010585f3ee8b8153c/pki/<random-hash>/peers$ ls
ca.crt me.crt me.key
When ran the openssl command to check the before and after dates for server.crt in clients and me.crt in peers directory, it showed that these certs were indeed expired.
/mnt/master-vol-010585f3ee8b8153c/pki/<random-hash>/clients$ openssl x509 -in server.crt -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 2348723493287432894 (0x2343243rfs)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = etcd-clients-ca
Validity
Not Before: Nov 5 23:26:23 2019 GMT
Not After : Nov 6 23:29:30 2020 GMT <<-------- so it expired last week!
Subject: CN = etcd-a
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
What are these certs used for?
On further googling I found that these certificates have a hardcoded duration of one year to expire. The certificates are used to communicate with local etcd members and kubeapi server.
So the issue was the etcd was not able to rotate these certificates which is an issue with their version lower than 3.0.2xxx. Read More
Quick fix
To do a quick fix all you need to do is inside your master k8s node restart the following containers:
- k8s_etcd-manager_etcd-manager-events-xxxxxx
- k8s_etcd-manager_etcd-manager-main-xxxxx
docker ps | grep etcd
docker restart <CONTAINER-ID for k8s_etcd-manager_etcd-manager-events-xxxxxx>
docker restart <CONTAINER-ID for k8s_etcd-manager_etcd-manager-main-xxxxx>
Now the certificates should be regenerated in both the EBS volumes for etcd and you should be good.
Running component status check with: kubectl get cs should give you healthy for your etcd nodes now.
kubectl get cs
NAME STATUS
etcd-0 Healthy
controller-manager Healthy
scheduler Healthy
etcd-1 Healthy
Kops have mentioned the issue on their website as well https://kops.sigs.k8s.io/advisories/etcd-manager-certificate-expiration/
For future:
Upgrade etcd-manager. etcd-manager version >= 3.0.20200428 manages certificate lifecycle and will automatically request new certificates before expiration.