By default kubernetes architecture is designed to be highly available all the time but even then there is a chance that container applications can still experience downtime if a node crashes or we intend to upgrade the cluster system itself which may require nodes to be replaced. When pods are deployed they don’t necessarily spread evenly on all the nodes in the cluster. Kubernetes scheduler will put the pods based on the resource available on nodes for example if we have 4 pods deployed for our application which has 4 nodes if one of the worker-node like node-4 was super busy occupied and busy, then scheduler may schedule 2 on one worker-node-1, 1 on worker-node-2 and another on worker-node-3. Therefore nothing was scheduled on worker node 4. This situation becomes an issue if we are trying to drain nodes during upgrade or remove extra nodes which may have some application pods running already. So if one of the nodes with running pod is removed it might cause a downtime.
In order to solve this issue we can tell kubernetes to always have a minimum number of healthy pods running at the time, so that during upgrade or any node catastrophe, the application still is able to serve the incoming requests. This is possible with Pod Disruption Budget resource in kubernetes.
What is Pod Disruption Budget (PDB)?
Pod Disruption Budget allows us to handle voluntary disruptions to our nodes by making sure that required number of replicas are always running in the cluster if a node is being drained due to cluster being updated or when cluster is being scaled down.
poddisruptionbudget.yaml
the main components of the poddisruptionbudget file are as follows:
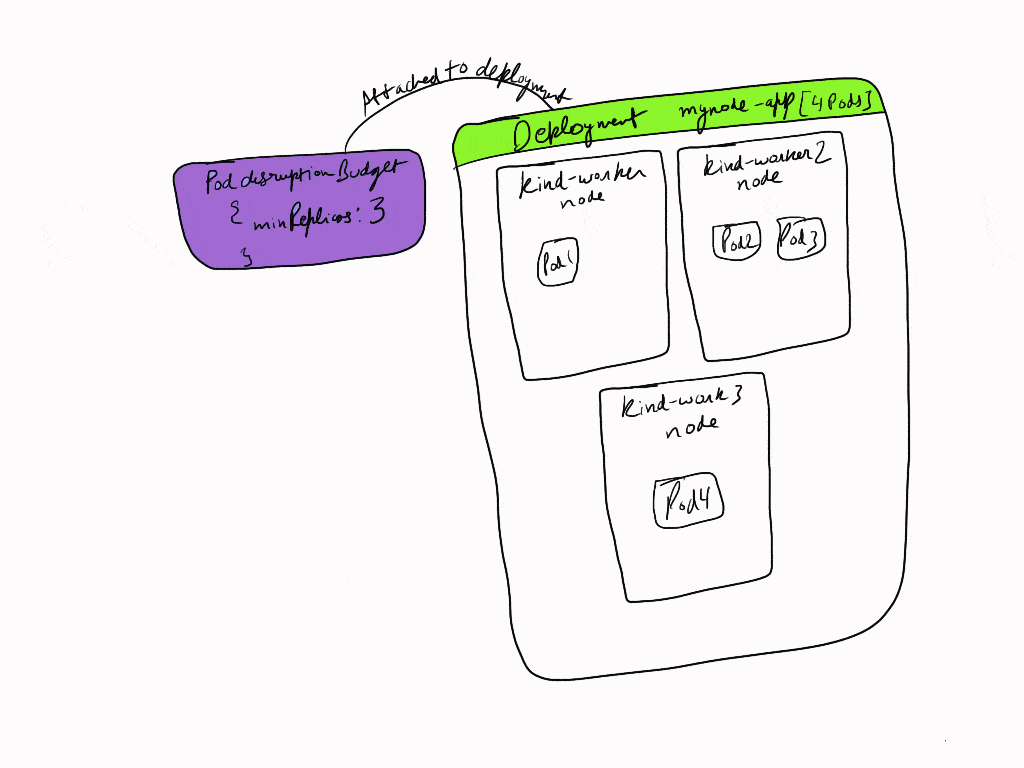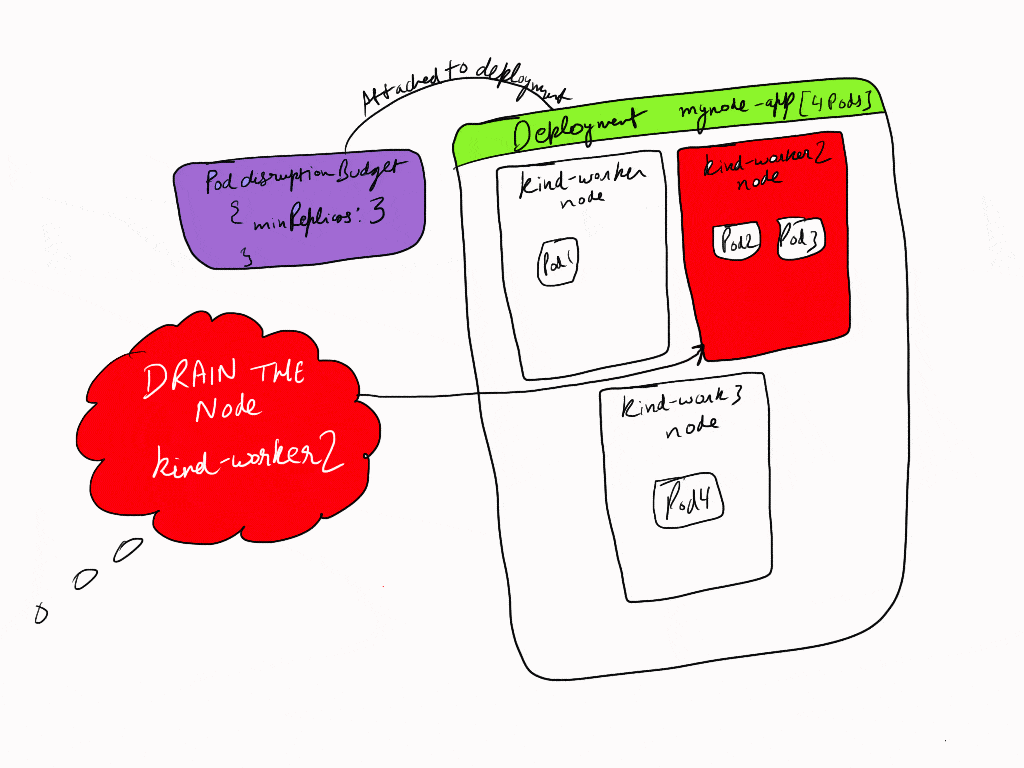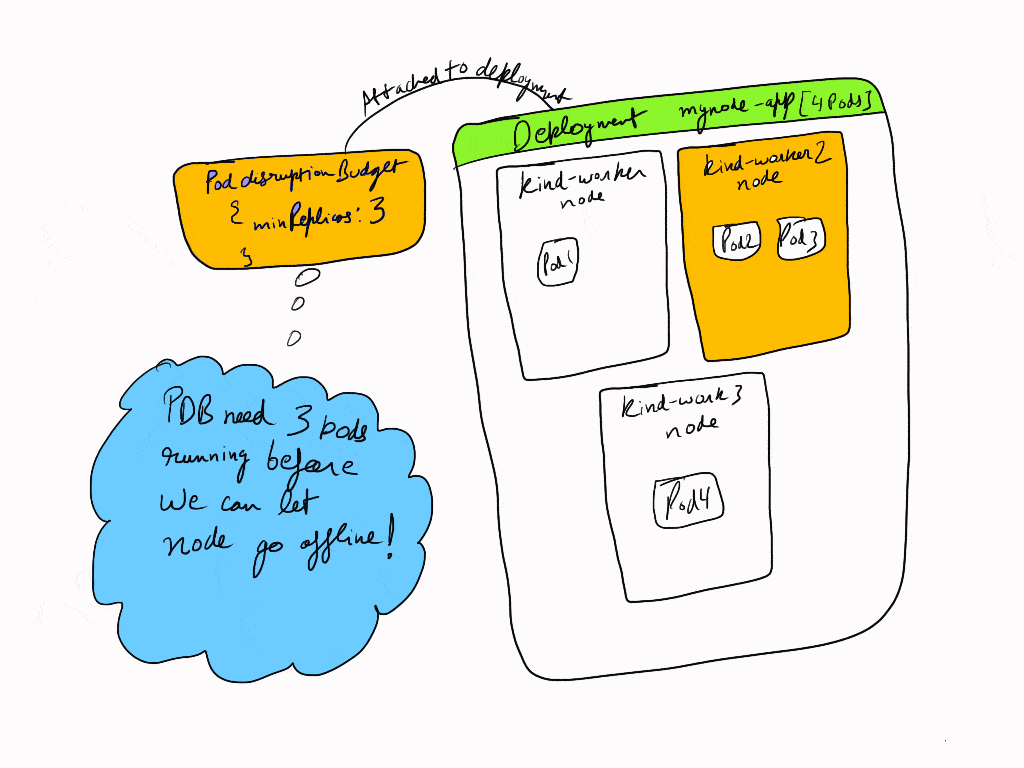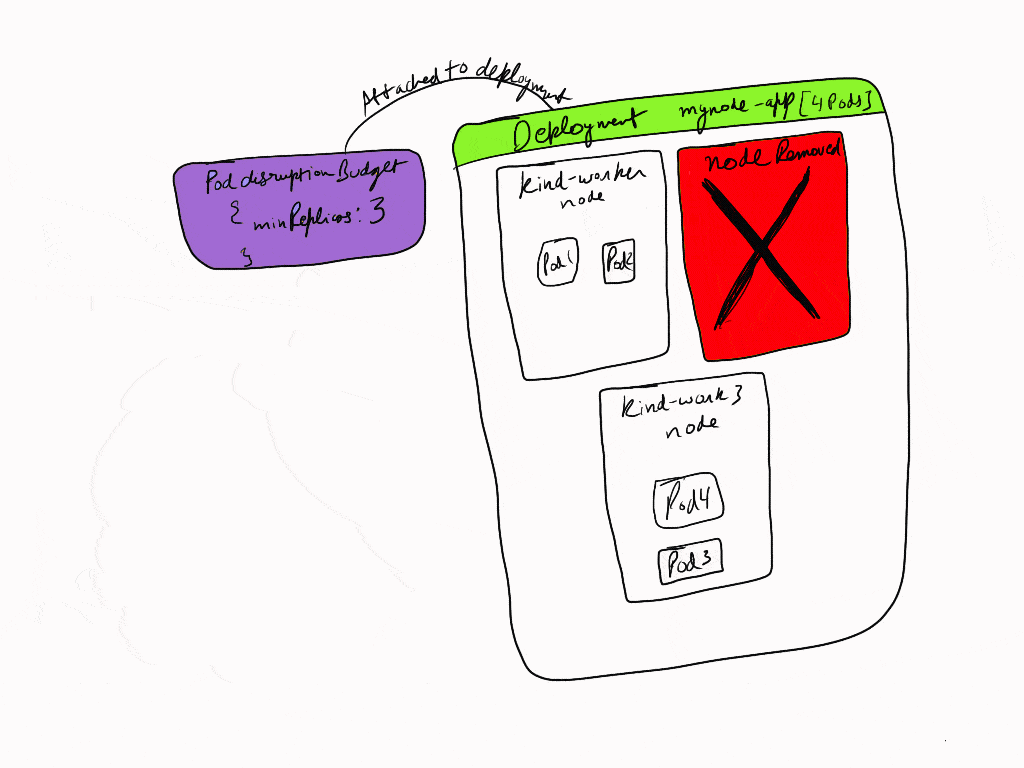
selector.matchLabels.app: This specifies the deployment we intend to control.spec.minAvailable: It defines the number of minimum pods to be always running in the cluster among all then nodes if one of the nodes is draining. We have set it to3pods to be always running.
Quick how-to tutorial
Components involved:
- kind cluster or AWS (any cluster that supports multiple nodes)
- a k8s deployable app (follow my previous tutorial)
- Pod Disruption budget config file.
Launching multiple nodes in kind(kubernetes in docker) cluster
With kind we can launch multiple nodes by running the kind create command with configmap defining number of workers and master nodes.
kind-config.yaml
After downloading the file just run:
kind create cluster --config kind-config.yaml
this will launch 3 worker node and one master mode:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready master 145m v1.18.2
kind-worker Ready <none> 144m v1.18.2
kind-worker2 Ready <none> 144m v1.18.2
kind-worker3 Ready <none> 144m v1.18.2
Note: minikube does not support multiple nodes at the time of writing this, so cannot show how node draining works and not see Pod Disruption Budget in action.
Github repo for the K8s deployable app: https://github.com/matharoo/mynode-app.
Setup Pod Disruption Budget
Now once we have app deployment running on our k8s cluster under nodejs namespace. We can now setup the above pod disruption budget object.
kubectl apply -f https://gist.githubusercontent.com/matharoo/364087b588bb660ee717ee1120258a0f/raw/83ec08fdd7b64f18cc5aa5875e3d547d4ffa3e9d/poddisruptionbudget.yaml -n nodejs
#Check if its setup properly by running:
kubectl get pdb -n nodejs
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
mynode-pdb 2 N/A 2 94s
Testing PDB by draining a node
To see PDB in works we will drain one of the nodes and then see how pods are moved to another node. In our example we have 4 replicas under our deployment which are spread over 3 worker nodes. Our pod disruption budget has minimumReplicas set to 3.
Before we drain the pods are spread on all the 3 worker nodes as below:

To drain a node we run:
kubectl drain kind-worker2

Now when we try to drain the node kind-worker2, then we see the error saying:
error when evicting pod "mynode-app-69cb8d797d-w4l65" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
So our PDB came into action and didn’t allow the node to be removed until the minimum number of replicas for the deployment becomes available again. Then kubernetes scheduler schedules the pod on the kind-worker and kind-worker3 node, after which the conditions for PDB are met again and it allows us to remove the node kind-worker2.
